



簡単に背景を説明します。私は CentOS 8 で稼働する 6 つのデータ SSD を備えた 10Gbit ファイル サーバーを所有しており、回線の飽和に苦労しています。帯域幅を 5 または 6Gbps に制限すれば、すべて問題ありません。以下は、Cockpit から取得したグラフで、すべてが順調であることを示しています (同時ユーザー数は約 850、上限は 5Gbps)。
残念ながら、さらに高く設定すると、帯域幅が大きな波のように変動します。通常、これはディスク (または SATA カード) が飽和している兆候であり、Windows ボックスでは次のように解決しました。
- 「リソース モニター」を開きます。
- 「ディスク」タブを選択します。
- 「キューの長さ」グラフを確認してください。キューの長さが 1 を超えているディスク/RAID はボトルネックです。アップグレードするか、負荷を減らしてください。
現在、CentOS 8 サーバーでこれらの症状が発生していますが、原因を特定するにはどうすればよいでしょうか? 私の SATA SSD は、次のように 3 つのソフトウェア RAID0 アレイに分割されています。
# cat /proc/mdstat
Personalities : [raid0]
md2 : active raid0 sdg[1] sdf[0]
7813772288 blocks super 1.2 512k chunks
md0 : active raid0 sdb[0] sdc[1]
3906764800 blocks super 1.2 512k chunks
md1 : active raid0 sdd[0] sde[1]
4000532480 blocks super 1.2 512k chunks`
iostat大きく変動し、通常は %iowait が高くなります。私が正しく理解していれば、md0 (sdb+sdc) の負荷が最も大きいことを示しているようです。しかし、これがボトルネックなのでしょうか? 結局のところ、%util は 100 にはほど遠いのです。
# iostat -xm 5
avg-cpu: %user %nice %system %iowait %steal %idle
7.85 0.00 35.18 50.02 0.00 6.96
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 106.20 57.20 0.89 0.22 3.20 0.00 2.93 0.00 136.87 216.02 26.82 8.56 3.99 0.92 14.96
sde 551.20 0.00 153.80 0.00 65.80 0.00 10.66 0.00 6.75 0.00 3.44 285.73 0.00 0.64 35.52
sdd 571.60 0.00 153.77 0.00 45.80 0.00 7.42 0.00 6.45 0.00 3.40 275.48 0.00 0.63 35.98
sdc 486.60 0.00 208.93 0.00 305.40 0.00 38.56 0.00 20.60 0.00 9.78 439.67 0.00 1.01 49.10
sdb 518.60 0.00 214.49 0.00 291.60 0.00 35.99 0.00 81.25 0.00 41.88 423.52 0.00 0.92 47.88
sdf 567.40 0.00 178.34 0.00 133.60 0.00 19.06 0.00 17.55 0.00 9.68 321.86 0.00 0.28 16.08
sdg 572.00 0.00 178.55 0.00 133.20 0.00 18.89 0.00 17.63 0.00 9.81 319.64 0.00 0.28 16.00
dm-0 5.80 0.80 0.42 0.00 0.00 0.00 0.00 0.00 519.90 844.75 3.69 74.62 4.00 1.21 0.80
dm-1 103.20 61.40 0.40 0.24 0.00 0.00 0.00 0.00 112.66 359.15 33.68 4.00 4.00 0.96 15.86
md1 1235.20 0.00 438.93 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 363.88 0.00 0.00 0.00
md0 1652.60 0.00 603.88 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 374.18 0.00 0.00 0.00
md2 1422.60 0.00 530.31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 381.72 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
5.14 0.00 22.00 72.86 0.00 0.00
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 34.00 37.40 0.15 0.15 5.20 0.00 13.27 0.00 934.56 871.59 64.34 4.61 4.15 0.94 6.74
sde 130.80 0.00 36.14 0.00 15.00 0.00 10.29 0.00 5.31 0.00 0.63 282.97 0.00 0.66 8.64
sdd 132.20 0.00 36.35 0.00 14.40 0.00 9.82 0.00 5.15 0.00 0.61 281.57 0.00 0.65 8.62
sdc 271.00 0.00 118.27 0.00 176.80 0.00 39.48 0.00 9.52 0.00 2.44 446.91 0.00 1.01 27.44
sdb 321.20 0.00 116.97 0.00 143.80 0.00 30.92 0.00 12.91 0.00 3.99 372.90 0.00 0.91 29.18
sdf 340.20 0.00 103.83 0.00 71.80 0.00 17.43 0.00 12.17 0.00 3.97 312.54 0.00 0.29 9.90
sdg 349.20 0.00 104.06 0.00 66.60 0.00 16.02 0.00 11.77 0.00 3.94 305.14 0.00 0.29 10.04
dm-0 0.00 0.80 0.00 0.01 0.00 0.00 0.00 0.00 0.00 1661.50 1.71 0.00 12.00 1.25 0.10
dm-1 38.80 42.20 0.15 0.16 0.00 0.00 0.00 0.00 936.60 2801.86 154.58 4.00 4.00 1.10 8.88
md1 292.60 0.00 111.79 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 391.22 0.00 0.00 0.00
md0 951.80 0.00 382.39 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 411.40 0.00 0.00 0.00
md2 844.80 0.00 333.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 403.71 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
一方、サーバーのパフォーマンスはひどいです。SSH 経由のキー入力はすべて数秒で登録され、GNOME デスクトップは事実上応答せず、ユーザーからは接続が切断されたという報告があります。コックピット チャートを表示したいのですが、ログインがタイムアウトします。帯域幅の制限はうまく機能しますが、残りの帯域幅をロック解除したいです。では、ボトルネックを特定するにはどうすればよいでしょうか? 何かアドバイスがあれば教えてください。
答え1
犯人は sda、つまり CentOS の磁気ディスクでした。ほとんどの証拠はそこにありました。誰かがコメントしたように (そして削除されたようですが)、sda、dm-0、dm-1 の待ち時間は疑わしいようです。確かに、dm-0 (ルート) と dm-1 (スワップ) も sda にあります。iotop の実行を見ると、ボトルネックは Gnome アクティビティの素早いフラッシュによってトリガーされたようで、その後 kswapd (スワップ) が作業を詰まらせました。Gnome を "init 3" で終了すると明らかに改善されましたが、これほど強力なマシンがアイドル状態のログイン画面で機能不全になるはずがありません。SMART は sda に 8000 以上の不良セクタがあると報告しています。私の推測では、これらの多くはスワップ領域にあり、スワップがシステムを機能不全に陥らせているのでしょう。
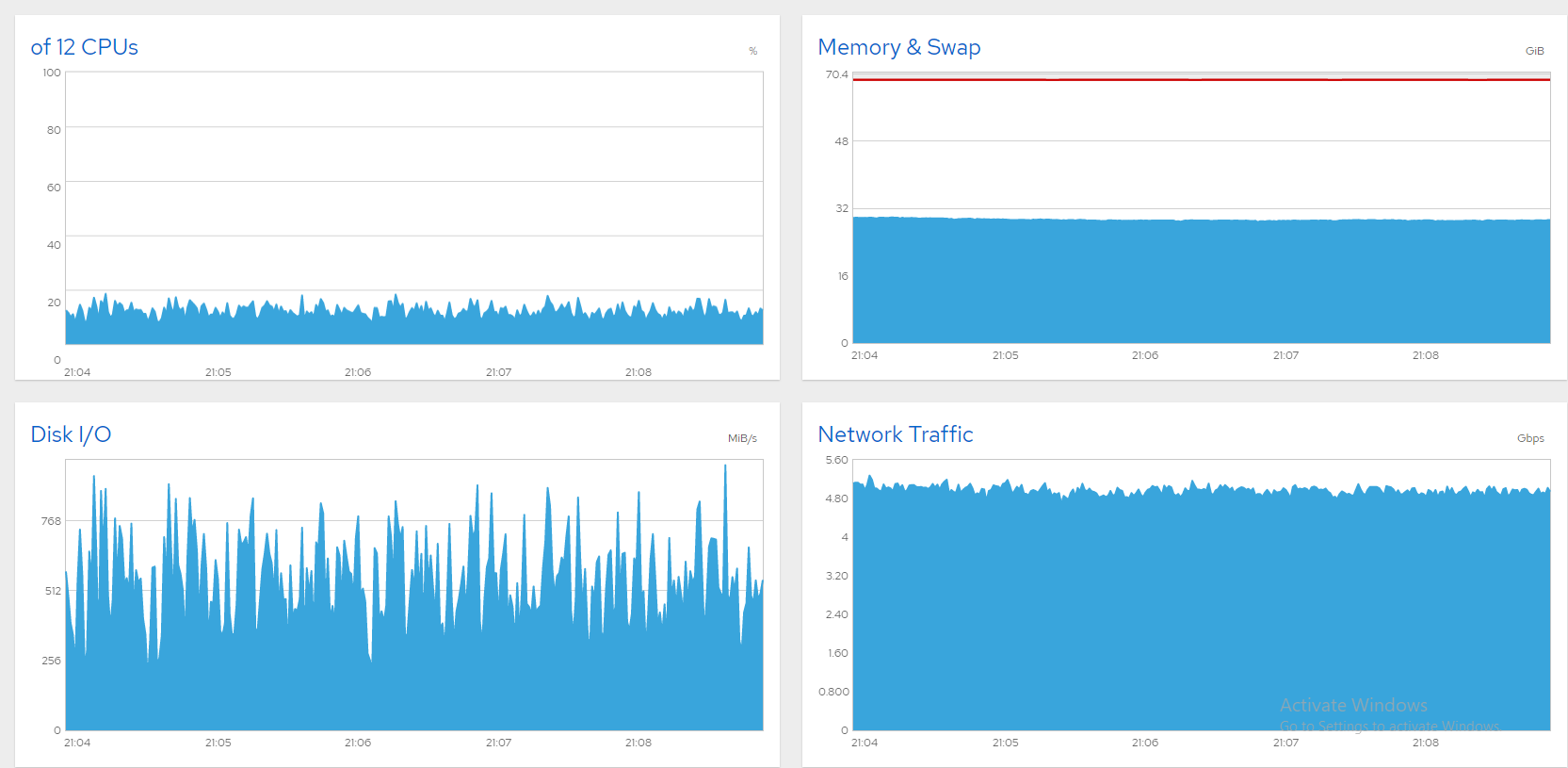
スワップを別のディスクに移動することも考えましたが、SDA を交換する方が現実的に思えました。CloneZilla でディスクのクローンを開始しましたが、3 時間かかると見積もられており、新規インストールの方が速いため、それを採用しました。これでサーバーは順調に動作しています。これは、1300 以上のファイルが 8Gbps で同時にストリーミングされていることを示すスクリーン ショットです。安定していて素晴らしいです。問題は解決しました。
