



간단한 배경지식; CentOS 8을 실행하는 6개의 데이터 SSD가 있는 10Gbit 파일 서버가 있는데 라인을 포화시키기 위해 애쓰고 있습니다. 대역폭을 5Gbps 또는 6Gbps로 제한하면 모든 것이 괜찮습니다. 다음은 모든 것이 양호함을 보여주는 Cockpit의 일부 차트입니다(동시 사용자 최대 850명, 최대 5Gbps).
불행하게도 더 높이 밀어 넣으면 대역폭이 거대한 파도로 변동합니다. 일반적으로 이는 포화된 디스크(또는 SATA 카드)의 신호이며 Windows 상자에서는 다음과 같이 해결했습니다.
- "리소스 모니터"를 엽니다.
- "디스크" 탭을 선택합니다.
- "큐 길이" 차트를 살펴보세요. 대기열 길이가 지속적으로 1을 초과하는 모든 디스크/레이드는 병목 현상이 발생합니다. 업그레이드하거나 부하를 줄이세요.
이제 CentOS 8 서버에서 이러한 증상이 나타납니다. 범인을 어떻게 찾아낼 수 있습니까? 내 SATA SSD는 다음과 같이 세 개의 소프트웨어 RAID0 어레이로 분할됩니다.
# cat /proc/mdstat
Personalities : [raid0]
md2 : active raid0 sdg[1] sdf[0]
7813772288 blocks super 1.2 512k chunks
md0 : active raid0 sdb[0] sdc[1]
3906764800 blocks super 1.2 512k chunks
md1 : active raid0 sdd[0] sde[1]
4000532480 blocks super 1.2 512k chunks`
iostat변동폭이 크며 일반적으로 %iowait가 높습니다. 내가 이 글을 읽고 있다면 md0(sdb+sdc)이 가장 큰 로드를 가지고 있음을 나타내는 것 같습니다. 하지만 병목 현상인가요? 결국 %util은 100에 가깝지 않습니다.
# iostat -xm 5
avg-cpu: %user %nice %system %iowait %steal %idle
7.85 0.00 35.18 50.02 0.00 6.96
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 106.20 57.20 0.89 0.22 3.20 0.00 2.93 0.00 136.87 216.02 26.82 8.56 3.99 0.92 14.96
sde 551.20 0.00 153.80 0.00 65.80 0.00 10.66 0.00 6.75 0.00 3.44 285.73 0.00 0.64 35.52
sdd 571.60 0.00 153.77 0.00 45.80 0.00 7.42 0.00 6.45 0.00 3.40 275.48 0.00 0.63 35.98
sdc 486.60 0.00 208.93 0.00 305.40 0.00 38.56 0.00 20.60 0.00 9.78 439.67 0.00 1.01 49.10
sdb 518.60 0.00 214.49 0.00 291.60 0.00 35.99 0.00 81.25 0.00 41.88 423.52 0.00 0.92 47.88
sdf 567.40 0.00 178.34 0.00 133.60 0.00 19.06 0.00 17.55 0.00 9.68 321.86 0.00 0.28 16.08
sdg 572.00 0.00 178.55 0.00 133.20 0.00 18.89 0.00 17.63 0.00 9.81 319.64 0.00 0.28 16.00
dm-0 5.80 0.80 0.42 0.00 0.00 0.00 0.00 0.00 519.90 844.75 3.69 74.62 4.00 1.21 0.80
dm-1 103.20 61.40 0.40 0.24 0.00 0.00 0.00 0.00 112.66 359.15 33.68 4.00 4.00 0.96 15.86
md1 1235.20 0.00 438.93 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 363.88 0.00 0.00 0.00
md0 1652.60 0.00 603.88 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 374.18 0.00 0.00 0.00
md2 1422.60 0.00 530.31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 381.72 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
5.14 0.00 22.00 72.86 0.00 0.00
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 34.00 37.40 0.15 0.15 5.20 0.00 13.27 0.00 934.56 871.59 64.34 4.61 4.15 0.94 6.74
sde 130.80 0.00 36.14 0.00 15.00 0.00 10.29 0.00 5.31 0.00 0.63 282.97 0.00 0.66 8.64
sdd 132.20 0.00 36.35 0.00 14.40 0.00 9.82 0.00 5.15 0.00 0.61 281.57 0.00 0.65 8.62
sdc 271.00 0.00 118.27 0.00 176.80 0.00 39.48 0.00 9.52 0.00 2.44 446.91 0.00 1.01 27.44
sdb 321.20 0.00 116.97 0.00 143.80 0.00 30.92 0.00 12.91 0.00 3.99 372.90 0.00 0.91 29.18
sdf 340.20 0.00 103.83 0.00 71.80 0.00 17.43 0.00 12.17 0.00 3.97 312.54 0.00 0.29 9.90
sdg 349.20 0.00 104.06 0.00 66.60 0.00 16.02 0.00 11.77 0.00 3.94 305.14 0.00 0.29 10.04
dm-0 0.00 0.80 0.00 0.01 0.00 0.00 0.00 0.00 0.00 1661.50 1.71 0.00 12.00 1.25 0.10
dm-1 38.80 42.20 0.15 0.16 0.00 0.00 0.00 0.00 936.60 2801.86 154.58 4.00 4.00 1.10 8.88
md1 292.60 0.00 111.79 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 391.22 0.00 0.00 0.00
md0 951.80 0.00 382.39 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 411.40 0.00 0.00 0.00
md2 844.80 0.00 333.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 403.71 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
반면 서버 성능은 형편없습니다. SSH를 통한 모든 키 입력은 등록하는 데 몇 초가 걸리며 GNOME 데스크탑은 사실상 응답하지 않으며 사용자는 연결이 끊겼다고 보고합니다. Cockpit 차트를 표시했지만 로그인 시간이 초과되었습니다. 대역폭을 제한하는 것은 훌륭하게 작동하지만 나머지는 잠금을 해제하고 싶습니다. 그렇다면 병목 현상을 어떻게 식별할 수 있습니까? 몇 가지 제안을 듣고 싶습니다!
답변1
범인은 CentOS 자기 디스크인 sda였습니다. 대부분의 증거가 그곳을 가리켰습니다. 누군가가 댓글을 달고 삭제한 것으로 보이므로 sda, dm-0 및 dm-1의 대기 시간이 의심스러워 보입니다. 물론 dm-0(루트) 및 dm-1(스왑)도 sda에 있습니다. iotop 실행을 관찰하면 병목 현상이 Gnome 활동의 빠른 플래시에 이어 kswapd(스왑)로 인해 작업이 막히면서 발생하는 것처럼 보였습니다. "init 3"으로 Gnome을 닫으면 확실히 개선되었지만 이렇게 강력한 시스템이 유휴 로그인 화면으로 인해 손상될 수는 없습니다. SMART는 또한 sda에서 8000개 이상의 불량 섹터를 보고합니다. 내 생각에는 이들 중 다수가 스왑 공간에 있어서 스왑으로 인해 시스템이 손상되는 것 같습니다.
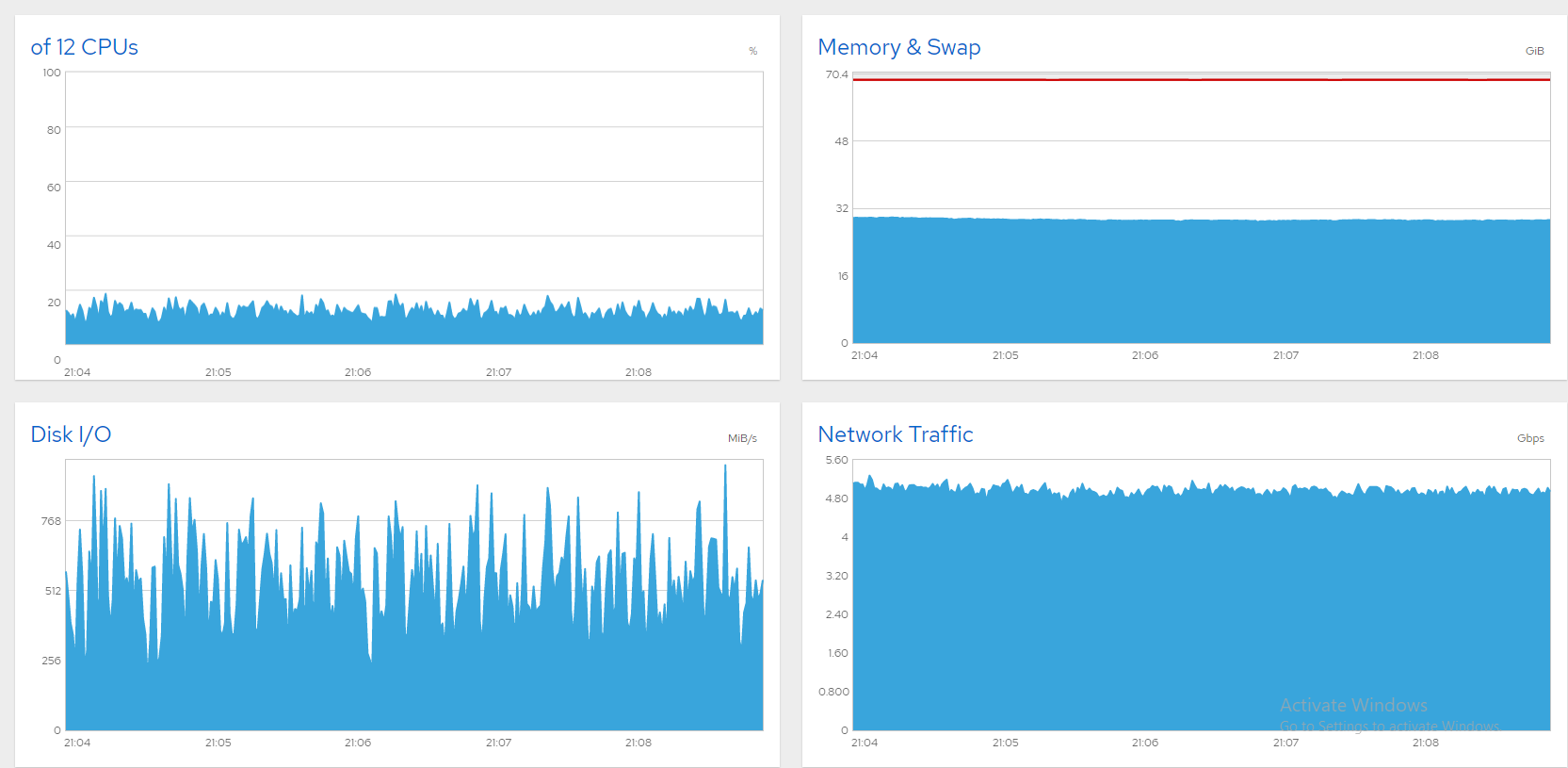
한 가지 생각은 스왑을 다른 디스크로 옮기는 것이었지만 sda를 교체하는 것이 더 실용적으로 보였습니다. CloneZilla를 사용하여 디스크 복제를 시작했지만 예상 시간은 3시간이었고 새로 설치하는 것이 더 빠르기 때문에 그렇게 했습니다. 이제 서버가 잘 돌아가고 있어요! 다음은 8Gbps를 통해 동시에 스트리밍되는 1300개 이상의 파일을 보여주는 스크린샷입니다. 훌륭하고 안정적입니다. 문제 해결됨!
