


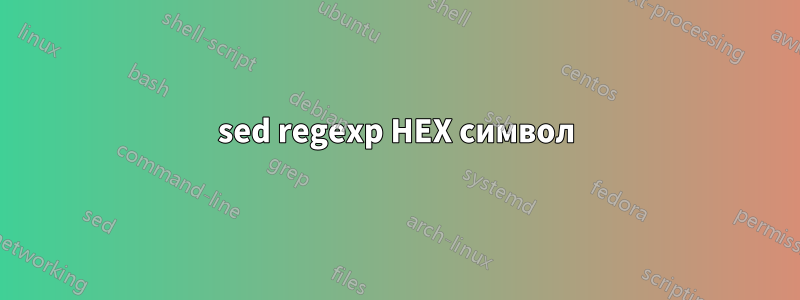
У меня есть следующая строка
echo -e "a12\x8fb12\x9f" | xxd
0000000: 6131 328f 6231 329f 0a a12.b12..
и хотите удалить последовательность 12\x9fи 12\x8fс sed.
Я могу сделать это с помощью этой команды
sed -e 's_12\x8f__g' -e 's_12\x9f__g'
но почему эта команда не работает?
sed -e 's_12[\x8f\x9f]__g'
решение1
Это может быть связано с тем, что [...]совпадения по символу. sedбудут пытаться сопоставить символы с диапазоном, указанным в [...]. В локалях UTF-8 вы можете встретить только \x8fкак часть многобайтового символа. Вы заметите, что .не совпадает и по нему (и это требование POSIX).
Например:
sed 's/[eé\xa9]//'
не имело бы смысла. éявляется символом (закодированным как 0xc3 0xa9), 0xa9 не является символом, а представляет собой байт, может быть найден внутри символа (например, é), eявляется символом (закодированным как 0x65). Вы не можете ожидать, sedчто каким-то образом сможете сопоставить 0xa9 как внутри символа, так и в качестве байта.
Чтобы сопоставить произвольные байтовые данные стекстутилита вроде sed, вам нужно будет использовать локаль, где символы являются байтами, это типичный случай дляLC_ALL=C.
LC_ALL=C sed 's/12[\x8f\x9f]//g'
Или переносимо:
LC_ALL=C sed "$(printf 's/12[\217\237]//g')"
Обратите внимание, что вы не можете ожидать, что данные, содержащие символы NUL (или которые не заканчиваются символом новой строки или где символы новой строки находятся на расстоянии более нескольких килобайт) будут обрабатываться переносимо с помощью . В этом случае sedиспользуйте вместо этого .perl -p/-n