



快速背景;我有一個 10Gbit 檔案伺服器,帶有六個運行 CentOS 8 的資料 SSD,我正在努力使線路飽和。如果我將頻寬限制在 5 或 6Gbps,一切都很好。以下是 Cockpit 中的一些圖表,顯示一切正常(約 850 個並髮用戶,5Gbps 上限)。
不幸的是,當我推得更高時,頻寬會出現巨大的波動。通常這是磁碟(或 SATA 卡)飽和的標誌,在 Windows 機器上我已經解決了這個問題,如下所示:
- 開啟“資源監視器”。
- 選擇“磁碟”選項卡。
- 觀看“佇列長度”圖表。任何佇列長度穩定在 1 以上的磁碟/raid 都是瓶頸。升級它或減少它的負載。
現在我在 CentOS 8 伺服器中看到這些症狀,但我該如何找出罪魁禍首?我的 SATA SSD 分為三個軟體 RAID0 陣列,如下所示:
# cat /proc/mdstat
Personalities : [raid0]
md2 : active raid0 sdg[1] sdf[0]
7813772288 blocks super 1.2 512k chunks
md0 : active raid0 sdb[0] sdc[1]
3906764800 blocks super 1.2 512k chunks
md1 : active raid0 sdd[0] sde[1]
4000532480 blocks super 1.2 512k chunks`
iostat波動劇烈並且通常具有較高的 %iowait。如果我沒看錯的話,似乎表示 md0 (sdb+sdc) 的負載最大。但這是瓶頸嗎?畢竟,%util 遠不及 100。
# iostat -xm 5
avg-cpu: %user %nice %system %iowait %steal %idle
7.85 0.00 35.18 50.02 0.00 6.96
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 106.20 57.20 0.89 0.22 3.20 0.00 2.93 0.00 136.87 216.02 26.82 8.56 3.99 0.92 14.96
sde 551.20 0.00 153.80 0.00 65.80 0.00 10.66 0.00 6.75 0.00 3.44 285.73 0.00 0.64 35.52
sdd 571.60 0.00 153.77 0.00 45.80 0.00 7.42 0.00 6.45 0.00 3.40 275.48 0.00 0.63 35.98
sdc 486.60 0.00 208.93 0.00 305.40 0.00 38.56 0.00 20.60 0.00 9.78 439.67 0.00 1.01 49.10
sdb 518.60 0.00 214.49 0.00 291.60 0.00 35.99 0.00 81.25 0.00 41.88 423.52 0.00 0.92 47.88
sdf 567.40 0.00 178.34 0.00 133.60 0.00 19.06 0.00 17.55 0.00 9.68 321.86 0.00 0.28 16.08
sdg 572.00 0.00 178.55 0.00 133.20 0.00 18.89 0.00 17.63 0.00 9.81 319.64 0.00 0.28 16.00
dm-0 5.80 0.80 0.42 0.00 0.00 0.00 0.00 0.00 519.90 844.75 3.69 74.62 4.00 1.21 0.80
dm-1 103.20 61.40 0.40 0.24 0.00 0.00 0.00 0.00 112.66 359.15 33.68 4.00 4.00 0.96 15.86
md1 1235.20 0.00 438.93 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 363.88 0.00 0.00 0.00
md0 1652.60 0.00 603.88 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 374.18 0.00 0.00 0.00
md2 1422.60 0.00 530.31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 381.72 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
5.14 0.00 22.00 72.86 0.00 0.00
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 34.00 37.40 0.15 0.15 5.20 0.00 13.27 0.00 934.56 871.59 64.34 4.61 4.15 0.94 6.74
sde 130.80 0.00 36.14 0.00 15.00 0.00 10.29 0.00 5.31 0.00 0.63 282.97 0.00 0.66 8.64
sdd 132.20 0.00 36.35 0.00 14.40 0.00 9.82 0.00 5.15 0.00 0.61 281.57 0.00 0.65 8.62
sdc 271.00 0.00 118.27 0.00 176.80 0.00 39.48 0.00 9.52 0.00 2.44 446.91 0.00 1.01 27.44
sdb 321.20 0.00 116.97 0.00 143.80 0.00 30.92 0.00 12.91 0.00 3.99 372.90 0.00 0.91 29.18
sdf 340.20 0.00 103.83 0.00 71.80 0.00 17.43 0.00 12.17 0.00 3.97 312.54 0.00 0.29 9.90
sdg 349.20 0.00 104.06 0.00 66.60 0.00 16.02 0.00 11.77 0.00 3.94 305.14 0.00 0.29 10.04
dm-0 0.00 0.80 0.00 0.01 0.00 0.00 0.00 0.00 0.00 1661.50 1.71 0.00 12.00 1.25 0.10
dm-1 38.80 42.20 0.15 0.16 0.00 0.00 0.00 0.00 936.60 2801.86 154.58 4.00 4.00 1.10 8.88
md1 292.60 0.00 111.79 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 391.22 0.00 0.00 0.00
md0 951.80 0.00 382.39 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 411.40 0.00 0.00 0.00
md2 844.80 0.00 333.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 403.71 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
同時伺服器效能也很糟糕。透過 SSH 進行的每次按鍵都需要幾秒鐘的時間來註冊,GNOME 桌面幾乎沒有回應,使用者報告連線中斷。我會顯示 Cockpit 圖表,但登入逾時。限制頻寬效果很好,但我想解鎖其餘部分。那麼如何辨識瓶頸呢?我很想得到一些建議!
答案1
罪魁禍首是 sda(CentOS 磁碟)。大多數證據都指向那裡。正如有人評論的那樣(似乎已經刪除),sda、dm-0 和 dm-1 上的等待時間看起來很可疑。果然,dm-0(root)和dm-1(swap)也在sda上。觀察 iotop 的運作情況,瓶頸似乎是由 Gnome 活動的快速閃光引發的,隨後 kswapd(交換)堵塞了工作。用「init 3」關閉 Gnome 確實取得了明顯的進步,但是如此強大的機器不可能因為空閒的登入畫面而癱瘓。 SMART 也在 sda 上報告了 8000 多個壞扇區。我的猜測是其中許多都在交換空間中,導致交換損壞系統。
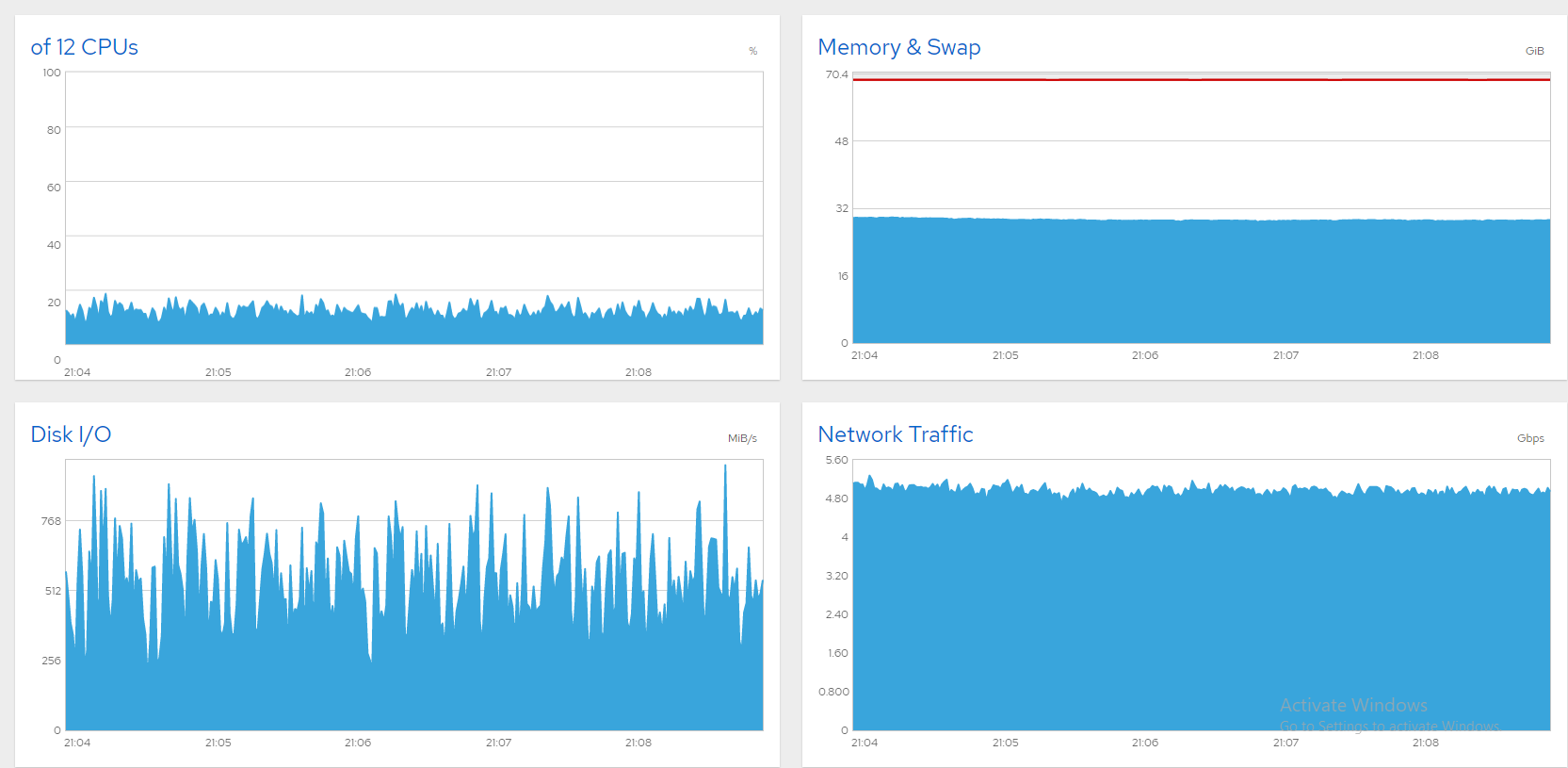
一種想法是將交換區移至另一個磁碟,但替換 sda 似乎更實用。我使用 CloneZilla 啟動了磁碟克隆,但估計需要 3 小時,而且全新安裝會更快,所以我就這麼做了。現在伺服器運作良好!這是一個螢幕截圖,顯示 1300 多個檔案以超過 8Gbps 的速度同時傳輸,效果良好且穩定。問題解決了!
