



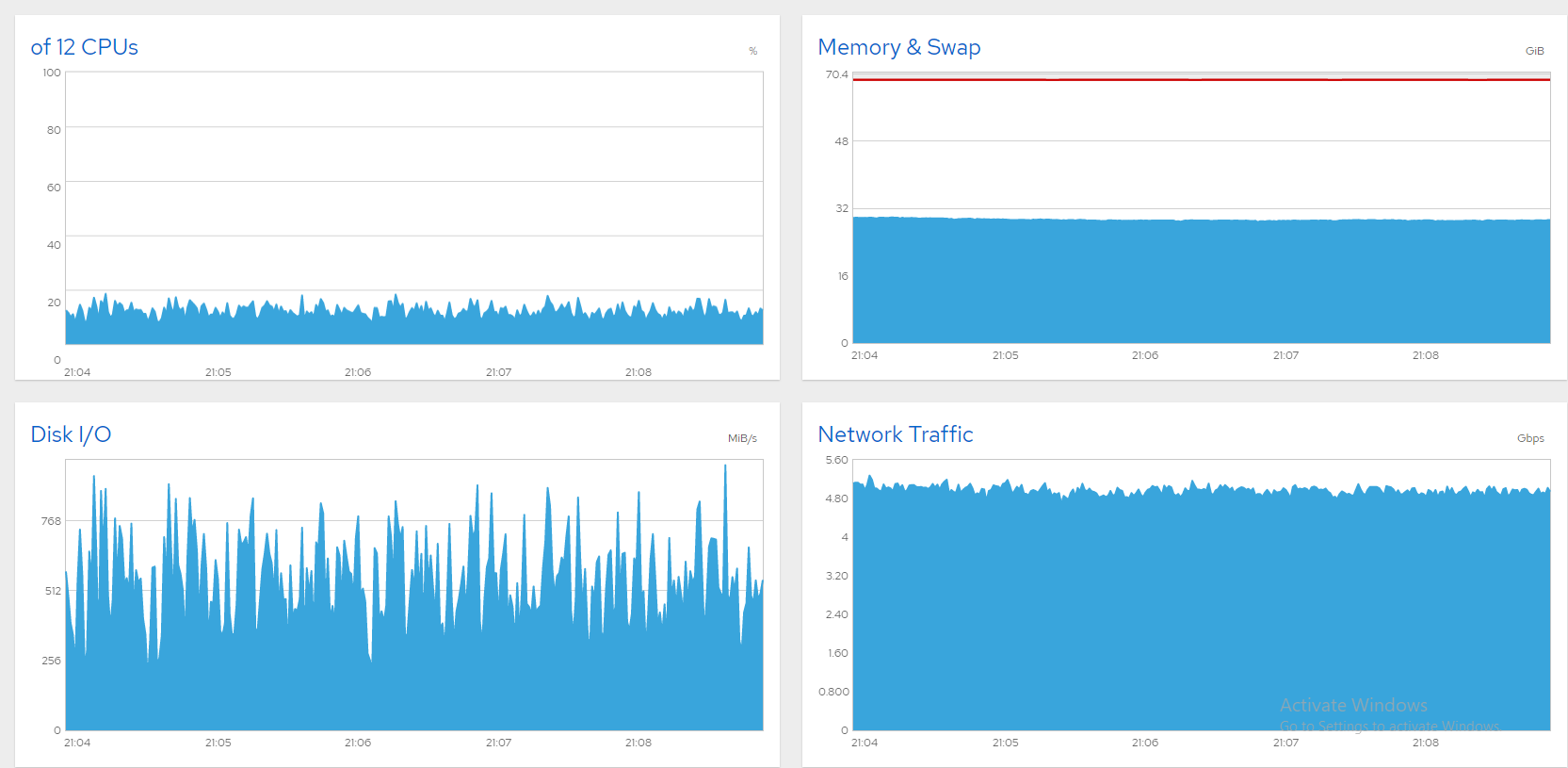
Kurzer Hintergrund: Ich habe einen 10-Gbit-Dateiserver mit sechs Daten-SSDs, auf denen CentOS 8 läuft, und ich habe Mühe, die Leitung voll auszulasten. Alles ist in Ordnung, wenn ich die Bandbreite auf 5 oder 6 Gbit/s begrenze. Hier sind einige Diagramme von Cockpit, die zeigen, dass alles in Ordnung ist (~850 gleichzeitige Benutzer, 5 Gbit/s-Begrenzung).
Leider schwankt die Bandbreite in großen Wellen, wenn ich sie höher schiebe. Normalerweise ist das ein Zeichen für eine gesättigte Festplatte (oder SATA-Karte), und auf Windows-Rechnern habe ich das folgendermaßen gelöst:
- Öffnen Sie den „Ressourcenmonitor“.
- Wählen Sie die Registerkarte „Datenträger“.
- Beobachten Sie die Diagramme zur „Warteschlangenlänge“. Jede Festplatte/jeder RAID mit einer Warteschlangenlänge von konstant über 1 ist ein Engpass. Aktualisieren Sie sie/ihn oder reduzieren Sie ihre Belastung.
Jetzt sehe ich diese Symptome auf einem CentOS 8-Server, aber wie finde ich den Übeltäter? Meine SATA-SSDs sind in drei Software-RAID0-Arrays aufgeteilt, wie folgt:
# cat /proc/mdstat
Personalities : [raid0]
md2 : active raid0 sdg[1] sdf[0]
7813772288 blocks super 1.2 512k chunks
md0 : active raid0 sdb[0] sdc[1]
3906764800 blocks super 1.2 512k chunks
md1 : active raid0 sdd[0] sde[1]
4000532480 blocks super 1.2 512k chunks`
iostatschwankt stark und hat normalerweise einen hohen %iowait. Wenn ich das richtig lese, scheint es darauf hinzudeuten, dass md0 (sdb+sdc) die größte Last hat. Aber ist das ein Engpass? Schließlich liegt %util nicht annähernd bei 100.
# iostat -xm 5
avg-cpu: %user %nice %system %iowait %steal %idle
7.85 0.00 35.18 50.02 0.00 6.96
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 106.20 57.20 0.89 0.22 3.20 0.00 2.93 0.00 136.87 216.02 26.82 8.56 3.99 0.92 14.96
sde 551.20 0.00 153.80 0.00 65.80 0.00 10.66 0.00 6.75 0.00 3.44 285.73 0.00 0.64 35.52
sdd 571.60 0.00 153.77 0.00 45.80 0.00 7.42 0.00 6.45 0.00 3.40 275.48 0.00 0.63 35.98
sdc 486.60 0.00 208.93 0.00 305.40 0.00 38.56 0.00 20.60 0.00 9.78 439.67 0.00 1.01 49.10
sdb 518.60 0.00 214.49 0.00 291.60 0.00 35.99 0.00 81.25 0.00 41.88 423.52 0.00 0.92 47.88
sdf 567.40 0.00 178.34 0.00 133.60 0.00 19.06 0.00 17.55 0.00 9.68 321.86 0.00 0.28 16.08
sdg 572.00 0.00 178.55 0.00 133.20 0.00 18.89 0.00 17.63 0.00 9.81 319.64 0.00 0.28 16.00
dm-0 5.80 0.80 0.42 0.00 0.00 0.00 0.00 0.00 519.90 844.75 3.69 74.62 4.00 1.21 0.80
dm-1 103.20 61.40 0.40 0.24 0.00 0.00 0.00 0.00 112.66 359.15 33.68 4.00 4.00 0.96 15.86
md1 1235.20 0.00 438.93 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 363.88 0.00 0.00 0.00
md0 1652.60 0.00 603.88 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 374.18 0.00 0.00 0.00
md2 1422.60 0.00 530.31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 381.72 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
avg-cpu: %user %nice %system %iowait %steal %idle
5.14 0.00 22.00 72.86 0.00 0.00
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 34.00 37.40 0.15 0.15 5.20 0.00 13.27 0.00 934.56 871.59 64.34 4.61 4.15 0.94 6.74
sde 130.80 0.00 36.14 0.00 15.00 0.00 10.29 0.00 5.31 0.00 0.63 282.97 0.00 0.66 8.64
sdd 132.20 0.00 36.35 0.00 14.40 0.00 9.82 0.00 5.15 0.00 0.61 281.57 0.00 0.65 8.62
sdc 271.00 0.00 118.27 0.00 176.80 0.00 39.48 0.00 9.52 0.00 2.44 446.91 0.00 1.01 27.44
sdb 321.20 0.00 116.97 0.00 143.80 0.00 30.92 0.00 12.91 0.00 3.99 372.90 0.00 0.91 29.18
sdf 340.20 0.00 103.83 0.00 71.80 0.00 17.43 0.00 12.17 0.00 3.97 312.54 0.00 0.29 9.90
sdg 349.20 0.00 104.06 0.00 66.60 0.00 16.02 0.00 11.77 0.00 3.94 305.14 0.00 0.29 10.04
dm-0 0.00 0.80 0.00 0.01 0.00 0.00 0.00 0.00 0.00 1661.50 1.71 0.00 12.00 1.25 0.10
dm-1 38.80 42.20 0.15 0.16 0.00 0.00 0.00 0.00 936.60 2801.86 154.58 4.00 4.00 1.10 8.88
md1 292.60 0.00 111.79 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 391.22 0.00 0.00 0.00
md0 951.80 0.00 382.39 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 411.40 0.00 0.00 0.00
md2 844.80 0.00 333.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 403.71 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Die Serverleistung ist derweil grauenhaft. Jeder Tastendruck über SSH dauert Sekunden, bis er registriert wird, der GNOME-Desktop reagiert praktisch nicht mehr und Benutzer melden Verbindungsabbrüche. Ich würde Cockpit-Diagramme anzeigen, aber die Anmeldung läuft ab. Die Bandbreitenbegrenzung funktioniert wunderbar, aber ich würde den Rest gerne freigeben. Wie kann ich also die Engpässe identifizieren? Ich würde mich über einige Vorschläge freuen!
Antwort1
Der Übeltäter war sda, die magnetische CentOS-Festplatte. Die meisten Beweise deuteten darauf hin. Wie jemand kommentierte (und anscheinend gelöscht hat), sehen die Wartezeiten auf sda, dm-0 und dm-1 verdächtig aus. Tatsächlich sind dm-0 (Root) und dm-1 (Swap) auch auf sda. Beim Beobachten von iotop beim Laufen schien der Engpass durch einen kurzen Gnome-Aktivitätsanstieg ausgelöst worden zu sein, gefolgt von kswapd (Swap), das die Arbeit behinderte. Das Schließen von Gnome mit „init 3“ brachte eine deutliche Verbesserung, aber es ist unmöglich, dass eine so leistungsstarke Maschine durch einen inaktiven Anmeldebildschirm lahmgelegt wird. SMART meldet auch über 8000 fehlerhafte Sektoren auf sda. Ich vermute, dass sich viele davon im Swap-Bereich befinden und Swaps das System lahmlegen.
Ein Gedanke war, den Swap auf eine andere Festplatte zu verschieben, aber das Ersetzen von sda schien praktischer. Ich habe mit CloneZilla einen Festplattenklon gestartet, aber das dauerte schätzungsweise 3 Stunden und eine Neuinstallation wäre schneller, also habe ich das gemacht. Jetzt läuft der Server super! Hier ist ein Screenshot, der über 1300 Dateien zeigt, die gleichzeitig über 8 Gbps gestreamt werden, schön und stabil. Problem gelöst!
